Twitter Header: Part 1
Intro
In this blog I'll be doing web reverse-engineering on Twitter. For context, I have a lot of experience with the Twitter "user" API, I've been "studying" it for about 1-2 years at this point. About 6 months ago I noticed that Twitter made a change to one of their headers, specifically the X-Client-Transaction-Id header. Previously, this header was meant to be set to the previous response from the server, just a few all lowercase characters. Now I noticed it looked more like a hash, like it was encrypted, it looked actually important now.
I'd like to say I started looking into it then, I didn't. In all reality, I never even added the header to anything I was running because I never noticed any difference after the header was changed. I wasn't using it before, I wasn't using it now. Now lets fast-forward to today, the reason I decided to look into this header.
One day Twitter added a new feature and I was very excited to see if I could figure out a way to bypass it, for fun, maybe a bug bounty. I tried everything and nothing worked, eventually I was left to just 1 more thing to look at, the X-Client-Transaction-Id header... I'm not sure exactly how much time I spent on it after that but I know it was quite a lot of fun and a very big learning experience for me!
One last thing before we get into this blog series. This series will cover deobfuscation using babel, however, I am not by any means a "professional" at deobfuscation. The code is messy and inefficient, mainly because it has the luxury of not needing to be fast for this use case. If you're trying to learn proper deobfuscation, I'd suggest learning it from someone else, like PianoMan for example, he has a series on his blog and GitHub.
Investigation
First things first, lets figure out where exactly this X-Client-Transaction-Id is being generated from. Twitter doesn't really obfuscate their files (foreshadowing) so to find this, we should be able to open the network tab and ctrl+f for X-Client-Transaction-Id.
Sure enough, when we do that, we see something come up with the URL https://abs.twimg.com/responsive-web/client-web/main.xxxxxx.js, this is one of the very first files loaded when you open twitter. If you click on the code it found too, you should see this:
function On(e) {
return async(n, t) => {
if (!Ln.test(n.host))
return t(n);
const a = {
...n
};
if (e.isTrue("rweb_client_transaction_id_enabled")) {
const {
method: e,
path: t
} = n;
try {
a.headers["x-client-transaction-id"] = await async function(e, n) {
Fn = Fn || new Promise((e => {
d.e("ondemand.s").then(d.bind(d, 471269)).then((n => e(n.default())))
}));
const t = await Fn;
return await t(e, n)
}(function(e) {
return (e || "").split("?")[0].trim()
}(t), e)
} catch (e) {
a.headers["x-client-transaction-id"] = btoa(`e:${e}`)
}
}
return t(a)
}
}
From this code, we can see that it's probably where our header is being set. It does appear to be referencing a function in another file though, to make it easier to find what we're looking for, lets set a breakpoint on the return await t(e, n) line. This way we can see exactly what params are passed in but also follow the execution and see where we need to look.
To get the breakpoint to trigger, you should just be able to scroll down the homepage a bit, you can also just refresh if you want. Eventually you should see something similar to this:
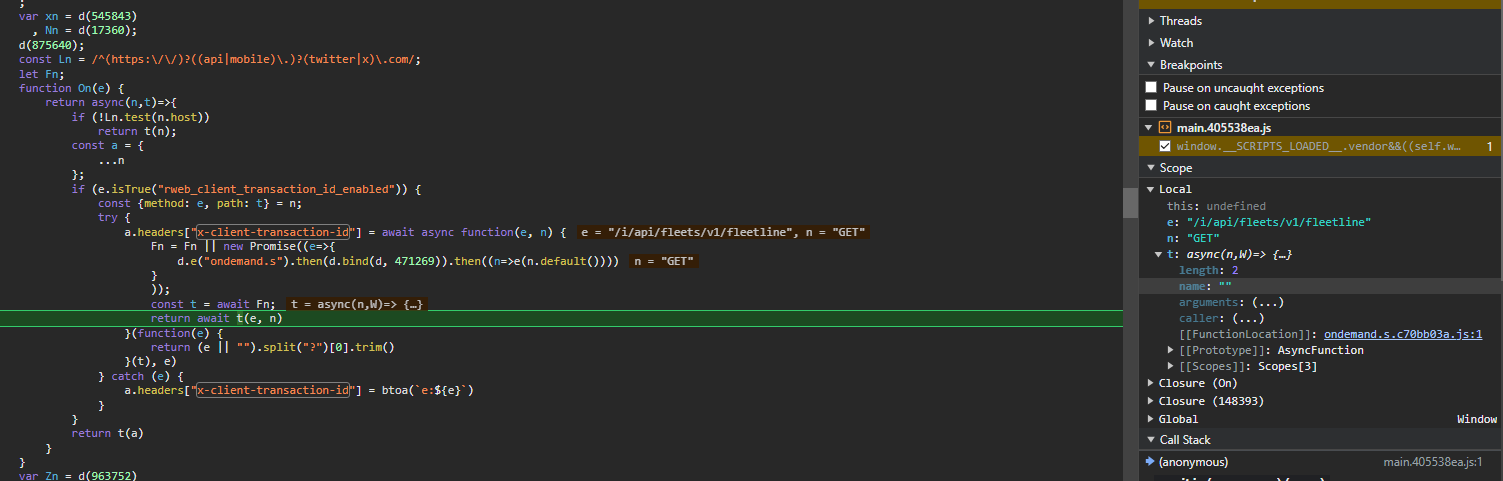
Now we know the first argument is the path, specifically without anything after ?, aka any argument. Then the second argument is the request method, fully uppercase. We can also see "FunctionLocation", this is exactly what we wanted. If you click the blue underlined words that say "ondemand.s.xxxxxx.js:1", you should be taken to the file that creates the X-Client-Transaction-Id header!
Oh wow, who would've expected this, it appears this file is obfuscated! Earlier when I said that Twitter doesn't obfuscate their files, I wasn't lying. In all the time I've been looking into Twitter, I've never seen them obfuscate a file even once. I guess you could argue their little javascript challenge is obfuscated since it uses HTML elements to do math but it's not exactly what you'd have in mind when you think of obfuscation. That fact alone made me all the more curious in this header, why is this header so important that it's the one obfuscated file on the entire website? Let's find out >:)
Deobfuscation
I will be covering the deobfuscation as I said previously, however, I won't be going super in-depth with it. I'll explain some stuff but for the most part, I'd still suggest reading other articles to learn proper deobfuscation!
First step is setting up my environment, I have this whole thing I usually just paste in every time to get me started. First I make 2 folders, one named output and one named source. Then I make a file named deobf.js, the contents of that file always start like this:
const fs = require('fs');
const t = require('@babel/types');
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const generate = require('@babel/generator').default;
const vm = require('vm')
const {
readFileSync,
writeFile,
writeFileSync,
} = require("fs");
const {
exit
} = require('process');
var output = ""
let beautify_opts = {
comments: true,
minified: false,
concise: false,
}
const script = readFileSync('./source/a.js', 'utf-8');
const AST = parser.parse(script, {})
var decryptFuncCtx = vm.createContext();
var decryptCode = ""
var decryptFuncName = ""
writeFileSync("output.txt", output, 'utf-8')
const final_code = generate(AST, beautify_opts).code;
fs.writeFileSync('./output/a.js', final_code);
Then I'll put my script to deobfuscate in ./source/a.js and do node deobf.js. I do this so I can have a properly pretty printed file that won't mess with the syntax. I've found a lot of the "JS pretty" stuff online will usually mess up the syntax with obfuscated scripts, babel never has for me.
Now we're onto the fun stuff, actually coding. First thing I notice is what's called "constant referencing", it looks like this:
const t = 64,
o = "mQSt",
u = "wBk5",
c = 546,
e = 174,
i = "lieW",
d = "PbRi",
f = 633,
a = "LRxI",
k = 451,
m = 88,
C = 287,
s = "*O3S",
h = 716,
S = 456,
q = 921;
Typically, when this is present in a "sample" (obfuscated file found in the "wild"), it will also have the same thing but as an object, it'll look like this:
const n = {
T: 702,
F: "I5Cj",
a: 267,
b: 232,
L: 413,
G: "PbRi",
o: 656,
h: 557,
m: 573,
N: "J7p6",
r: 687,
W: 611
}
Knowing this, I went to look for something like that in the script, of which I did find it. Those two things we will be focusing on first.
We can use a website called astexplorer.net to see what JS code looks like in an AST (abstract syntax tree). Specifically I'll look at it under @babel/parser. So according to the AST, our "constant dereference" visitor should be a VariableDeclarator. We need to make sure we don't accidentally get anything we're not supposed to in this though. To do this we will do some checks before replacing everything:
const constantReplacer = {
VariableDeclarator(path) {
const {node} = path;
if(!node.id || !node.init || (node.init.type != "StringLiteral" && node.init.type != "NumericLiteral") || node.id.type != "Identifier") {
return
}
if((node.init.type == "NumericLiteral" && node.init.value == 0) || (node.init.type == "StringLiteral" && node.init.value == "")) {
return
}
let binding = path.scope.getBinding(node.id.name)
if(!binding) {
return
}
for(var i = 0; i < binding.referencePaths.length; i++) {
binding.referencePaths[i].replaceWith(node.init)
}
path.remove()
}
}
To explain this code, I'd say we make sure the variable is either a string or int and it's not 0 or "". Then we get all the times that variable is used in the script, using path.scope.getBinding(node.id.name) with the referencePaths key. Any time the variable is used, just replace that use with the string or int itself. After we're done doing that, the variable should no longer be used, meaning we can remove it.
To do the object referencing it's very similar just with a bit of extra work:
const replaceObjSimple = {
VariableDeclarator(path) {
const {node} = path;
if(!node.id || !node.init || node.init.type != "ObjectExpression" || node.id.type != "Identifier" || node.init.properties.length < 1) {
return
}
var valid = true
var map = {}
for(var i = 0; i < node.init.properties.length; i++) {
var prop = node.init.properties[i]
if(!prop.key || !prop.value || prop.key.type != "Identifier" || (prop.value.type != "NumericLiteral" && prop.value.type != "StringLiteral")) {
valid = false
break
}
map[prop.key.name] = prop.value
}
if(!valid) {
return
}
path.scope.crawl()
let binding = path.scope.getBinding(node.id.name)
if(!binding) {
return
}
for(var i = 0; i < binding.referencePaths.length; i++) {
let refPath = binding.referencePaths[i].parentPath
if(refPath.node.type != "MemberExpression" || !refPath.node.property) {
continue
}
let key;
if(refPath.node.property.type == "Identifier") {
key = refPath.node.property.name
} else{
key = refPath.node.property.value
}
refPath.replaceWith(map[key])
}
path.remove()
}
}
So we check if the variable is an ObjectExpression, as the AST says it should be. We also make sure it has "properties". Now because of how those referencePaths work, the easiest way I've found to unreference these objects is to create a map of the key -> value and lookup the key used in the referencePath later.
To make the map, we kill two birds with one stone here. We validate every object property while also populating the map. Making sure every property is either an int or a string and the key has to be an Identifier. Some of you might see path.scope.crawl() and wonder what that means, it basically "crawls" the scope to update it, atleast that's how I think of it. The reason I use it is because there's a lot of situations where babel doesn't properly track changes and it can cause you to get really stupid errors.
The other differences here is we're doing binding.referencePaths[i].parentPath, parentPath is just the path that the current path belongs to. So if you have x["y"] and you're current on the path for x, then the parentPath is x["y"]. That's why I then go on to check for a MemberExpression type on that path. I then use it's "key" to select a key from the "map" and replace the object reference.
To make these 2 visitors run, I'm gonna add this code above the writeFileSync("output.txt", output, "utf-8") line:
// ! replace the `x = 123` and `y = "asd"` things
traverse(AST, constantReplacer)
// ! replace `const n = {T: 702}`
traverse(AST, replaceObjSimple)
This will be the only time I explain that. Anyway, now we can run this code and move on to whatever we have next! So, the thing I'm focused on right now is doing string deobfuscation, I'll need to work towards that.
In order to get all of our string obfuscation routines into a CallExpression, we need to handle 3 things:
/* 1 */ mr[(t = "hyP7", r = 661, o = 735, $(t - 252, o - 1061, t, r - 204, o - 6))]
/* 2 */ (a = "7d]D", k = -497, m = -404, C = -368, uo(k - -1644, a - 298, a, m - 199, C - 208))
/* 3 */
iu[function (n, t, W, r, u) {
return On(n - 247, W, r - 606, r - 38, u - 235);
}(1095, 0, "e9so", 1006, 1053)]
Putting the first two into ASTExplorer, we can see that they're both extremely similar. For simplicity’s sake, I won't make them into one visitor, however, they will be in the same traverse!
Replacing this is actually quite "complex" in some sense, therefore, I'll be doing this the laziest way possible though. First thing we need to do is identify that it's something we actually need to "correct":
if(!node.property || node.property.type != "SequenceExpression" || !node.property.expressions || node.property.expressions.length < 3) {
return
}
var callExprIndex = node.property.expressions.length-1
if(node.property.expressions[callExprIndex].type != "CallExpression") {
return
}
So we're checking if inside the MemberExpression is a SequenceExpression, if that SequenceExpression has a length of at least 3, and if the final element is a CallExpression. Now if you take time to look for a few occurrences of this in the script, you will see that it can have any amount of expressions. The easiest way I figured I'd do this was to loop over the expressions and add all AssignmentExpression type's to an array, specifically 2 arrays, one for their name and one for their value:
var values = []
var order = []
for(var i = 0; i < node.property.expressions.length; i++) {
var expr = node.property.expressions[i]
if(expr.type != "AssignmentExpression" || !expr.right || !expr.left) {
continue
}
values.push(generate(expr.right).code)
order.push(expr.left.name)
}
You can already see the laziness starting, instead of adding the actual values, I'm adding generate(expr.right).code. This is so I don't have to deal with negative numbers, binary expressions, etc. Like I said, this is the lazy way! The rest of this code is terrible, it also practically gets copy-pasted for the other 2 things we need to replace. Here's what I came up with:
let newArgs = []
for(var i = 0; i < node.property.expressions[callExprIndex].arguments.length; i++) {
let arg = node.property.expressions[callExprIndex].arguments[i]
let str = generate(arg).code
if(str.match(/[A-z]/g) == null) {
newArgs.push(arg)
continue
}
let key = str.match(/[A-z]/g)[0]
let index = order.indexOf(key)
str = str.replace(key, values[index])
if(str.match(/[0-9]/g) != null && str.match(/[0-9]/g).length > 1 && !str.match(/[A-z"]/g)) {
newArgs.push(t.numericLiteral(eval(str)))
continue
}
str = str.slice(1)
str = str.slice(0, -1)
newArgs.push(t.stringLiteral(str))
}
path.replaceWith(t.memberExpression(node.object, t.callExpression(node.property.expressions[callExprIndex].callee, newArgs), true))
In general, I'd say this is way easier than messing around with BinaryExpression's and UnaryExpression's and all that. I'll go over what's going on here and my general thought process though. So first, I'm using generate to create a string from the argument's node. I then go on to check if this string contains [A-z], this is because if it doesn't contain [A-z] then it can't possibly contain a variable to replace. Next I pull out the key by matching that same regex, then I get the index in the order array, I can use that index to get the value in the values array since they are 1:1. Next I need to ensure that I'm doing NumericLiteral and StringLiteral correctly. To ensure something is a number, I'll need to use 3 different tests because as it turns out, I ended up finding quite a few edge cases after trying to deobfuscate a few samples. Then for string's, I'm slicing off the first and last characters because they have " at the start and end, since I just used generate on them.
Previously I said that the code for all 3 of the things we're replacing would be quite similar, therefore, I won't be explaining the other 2 parts, instead I'll put all 3 parts here:
const replaceExprStmts = {
MemberExpression(path) {
const {node} = path;
if(!node.property || node.property.type != "SequenceExpression" || !node.property.expressions || node.property.expressions.length < 3) {
return
}
var callExprIndex = node.property.expressions.length-1
if(node.property.expressions[callExprIndex].type != "CallExpression") {
return
}
var values = []
var order = []
for(var i = 0; i < node.property.expressions.length; i++) {
var expr = node.property.expressions[i]
if(expr.type != "AssignmentExpression" || !expr.right || !expr.left) {
continue
}
values.push(generate(expr.right).code)
order.push(expr.left.name)
}
let newArgs = []
for(var i = 0; i < node.property.expressions[callExprIndex].arguments.length; i++) {
let arg = node.property.expressions[callExprIndex].arguments[i]
let str = generate(arg).code
if(str.match(/[A-z]/g) == null) {
newArgs.push(arg)
continue
}
let key = str.match(/[A-z]/g)[0]
let index = order.indexOf(key)
str = str.replace(key, values[index])
if(str.match(/[0-9]/g) != null && str.match(/[0-9]/g).length > 1 && !str.match(/[A-z"]/g)) {
newArgs.push(t.numericLiteral(eval(str)))
continue
}
str = str.slice(1)
str = str.slice(0, -1)
newArgs.push(t.stringLiteral(str))
}
path.replaceWith(t.memberExpression(node.object, t.callExpression(node.property.expressions[callExprIndex].callee, newArgs), true))
},
// ! same thing except ExpressionStatement, SequenceExpression
// ! example: (a = "7d]D", k = -497, m = -404, C = -368, uo(k - -1644, a - 298, a, m - 199, C - 208))
SequenceExpression(path) {
const {node} = path;
if(!node.expressions || node.expressions.length < 3) {
return
}
var callExprIndex = node.expressions.length-1
if(node.expressions[callExprIndex].type != "CallExpression") {
return
}
var values = []
var order = []
for(var i = 0; i < node.expressions.length; i++) {
var expr = node.expressions[i]
if(expr.type != "AssignmentExpression" || !expr.right || !expr.left) {
continue
}
values.push(generate(expr.right).code)
order.push(expr.left.name)
}
let newArgs = []
for(var i = 0; i < node.expressions[callExprIndex].arguments.length; i++) {
let arg = node.expressions[callExprIndex].arguments[i]
let str = generate(arg).code
if(str.match(/[A-z]/g) == null) {
newArgs.push(arg)
continue
}
let key = str.match(/[A-z]/g)[0]
let index = order.indexOf(key)
str = str.replace(key, values[index])
if(str.match(/[0-9]/g) != null && str.match(/[0-9]/g).length > 1 && !str.match(/[A-z"]/g)) {
newArgs.push(t.numericLiteral(eval(str)))
continue
}
str = str.slice(1)
str = str.slice(0, -1)
newArgs.push(t.stringLiteral(str))
}
path.replaceWith(t.callExpression(node.expressions[callExprIndex].callee, newArgs))
}
}
const replaceWeirdProxyCall = {
MemberExpression(path) {
const {node} = path;
if(!node.object || node.object.type != "Identifier" || !node.property || node.property.type != "CallExpression") {
return
}
if(!node.property.callee || node.property.callee.type != "FunctionExpression") {
return
}
let values = [generate(node.property.arguments[0]).code, generate(node.property.arguments[1]).code, generate(node.property.arguments[2]).code, generate(node.property.arguments[3]).code, generate(node.property.arguments[4]).code]
let order = [node.property.callee.params[0].name, node.property.callee.params[1].name, node.property.callee.params[2].name, node.property.callee.params[3].name, node.property.callee.params[4].name]
let newArgs = []
for(var i = 0; i < node.property.callee.body.body[0].argument.arguments.length; i++) {
let arg = node.property.callee.body.body[0].argument.arguments[i]
let str = generate(arg).code
if(str.match(/[A-z]/g) == null) {
newArgs.push(arg)
continue
}
let key = str.match(/[A-z]/g)[0]
let index = order.indexOf(key)
str = str.replace(key, values[index])
if(str.match(/[0-9]/g) != null && str.match(/[0-9]/g).length > 1&& !str.match(/[A-z"]/g)) {
newArgs.push(t.numericLiteral(eval(str)))
continue
}
str = str.slice(1)
str = str.slice(0, -1)
newArgs.push(t.stringLiteral(str))
}
path.replaceWith(t.memberExpression(node.object, t.callExpression(node.property.callee.body.body[0].argument.callee, newArgs), true))
}
}
You may notice that in replaceWeirdProxyCall the values or order aren't dynamically set. This is because in all my testing I'm 99.9% sure the values can only be 5 long and I didn't want to change that code to make it dynamic if I didn't have a reason to.
Alright, now if you remember from before, I said the goal right now is to do string deobfuscation. We've now made it to that point! To do string deobfuscation, we need to get the deobfuscation code into the "vm". The type of string obfuscation this script is using is very common, therefore, I know exactly what I need to do to get the code. I immediately noticed the function that returned an array of strings at the very bottom of the script, if you look at all uses of this function, you will find what's called a "shifter" function and the actual deobfuscation function. We need all 3 of these parts, I prefer to start at the "shifter", you could start at the array function as well if you wanted though. Here's the code I wrote:
const getStringDeobfFuncs = {
ExpressionStatement(path) {
const {node} = path;
if(!node.expression || node.expression.operator != "!" || !node.expression.prefix || !node.expression.argument || node.expression.argument.type != "CallExpression") {
return
}
// ! get array func
let binding = path.scope.getBinding(node.expression.argument.arguments[0].name)
if(!binding) {
return
}
decryptCode += generate(binding.path.node).code + "\n"
// ! get decrypt func
var bodyIndex = 0
for(var i = 0; i < node.expression.argument.callee.body.body.length; i++) {
if(node.expression.argument.callee.body.body[i].type == "FunctionDeclaration") {
bodyIndex = i
break
}
}
decryptFuncName = node.expression.argument.callee.body.body[bodyIndex].body.body[0].argument.callee.name
path.scope.crawl()
let binding1 = path.scope.getBinding(decryptFuncName)
if(!binding1){
return
}
decryptCode += generate(binding1.path.node).code + "\n"
decryptCode += generate(node).code + "\n"
binding1.path.remove()
binding.path.remove()
path.remove()
path.stop()
}
}
So the main deobfuscation function is somewhere in the body, in a FunctionDeclaration. Since you can't predict where that FunctionDeclaration will be every time, I loop over the body until I find it. The array function is always passed into the shifter as an argument.
This next part is gonna show my laziness again. Now if you read the script a little bit, you'll notice they're using what's called "proxy functions" to make these string obfuscation function calls, like this:
function oo(n, W, t, o, u) {
return MAIN_DEOBF_FUNC(u - -42, o);
}
function tn(n, W, t, r, o) {
return oo(0, 0, 0, t, o - -453);
}
tn(-63, 93, "#SGC", -46, -8)
There's a lot of ways to go about solving this, you could index each one of these proxy functions in a map, see how they interact with the inputs, then use that map to modify your CallExpression inputs with some fancy code. That's not lazy though, that takes a lot of effort, at least more effort than I'd like. The way I'm doing it is by going through and adding every proxy function to the code that get executed with the CallExpression in the VM context. The reason I'm saying this is because it causes an issue that you wouldn't have noticed until you went around and wrote the string deobfuscation function and tried running it. To sum it up, sometimes some proxy functions will be named the exact same name as the main deobfuscation function itself, since we're adding the proxy function code to the code that executes in the VM context, this causes an error since we now have 2 functions named the same thing in the same context/scope.
To get around this, I'll write a quick visitor to set the function name of any proxy function that shares the name of the deobfuscation function with a random name:
function makeid(length) {
let result = '';
const characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz';
const charactersLength = characters.length;
let counter = 0;
while (counter < length) {
result += characters.charAt(Math.floor(Math.random() * charactersLength));
counter += 1;
}
return result;
}
const replaceInterceptingFuncNames = {
FunctionDeclaration(path) {
const {node} = path;
if(!node.id || node.id.type != "Identifier" || node.id.name != decryptFuncName || !node.body || !node.body.body || node.body.body.length != 1) {
return
}
path.scope.crawl()
let binding = path.parentPath.scope.getBinding(node.id.name)
if(!binding) {
return
}
var ID = t.identifier(makeid(10))
for(var i = 0; i < binding.referencePaths.length; i++) {
binding.referencePaths[i].replaceWith(ID)
}
node.id = ID
}
}
Now we can hopefully deobfuscate strings, which is actually super easy since we're doing it the lazy way. I also already explained how I was doing it but I'll explain it a little more with the code:
const deobfStrings = {
CallExpression(path) {
const {node} = path;
if(!node.callee || node.callee.type != "Identifier" || !node.arguments || node.arguments.length < 2) {
return
}
var valid = true
for(var i = 0; i < node.arguments.length; i++) {
var arg = node.arguments[i]
let str = generate(arg).code
if(arg.type == "StringLiteral" || str == "NaN") {
continue
}
if(arg.type != "UnaryExpression" && arg.type != "BinaryExpression" && arg.type != "NumericLiteral") {
valid = false
break
}
if(str.match(/[A-z]/g) != null) {
valid = false
break
}
}
if(!valid) {
return
}
// ! the logic here is we want to get the function this is calling
// ! then we want to keep getting the nested function calls until we get to the final function, aka the decryptFuncName
let code = ""
path.scope.crawl()
let binding = path.scope.getBinding(node.callee.name)
if(!binding) {
// ! hopefully no binding will always mean that the function in question is `r`???
path.replaceWith(t.valueToNode(vm.runInContext(generate(node).code, decryptFuncCtx)))
return
}
// ! loop until we get to a place where we can't get a binding (aka hopefully the root function)
while(true){
if(!binding){
let a = generate(node).code
if(a[0] == decryptFuncName) {
a[0] = "asd"
}
code += a
break
}
code += generate(binding.path.node).code + "\n"
path.scope.crawl()
binding = binding.path.scope.getBinding(binding.path.node.body.body[0].argument.callee.name)
}
// ! now we should have all the code we need
path.replaceWith(t.valueToNode(vm.runInContext(code, decryptFuncCtx)))
}
}
So you see we first make sure it's valid. You should notice I actually completely skip over StringLiteral and NaN. This is because there wasn't any great way to validate strings in the arguments very well, since the way we do replaceExprStmts can be super buggy sometimes and produce "xxxxx\" - 111" for example. They design it like that on purpose, it never takes an arg like that and actually uses it in the main deobfuscation function so that little bug isn't a problem at all thankfully. The same idea applies to NaN, sometimes they do weird stuff that causes NaN but since it'll never actually use that value in the final function call, it doesn't matter.
Now to run this, you'll need to add the code from getStringDeobfFuncs to the decryptFuncCtx, I like to do this:
writeFileSync("output.js", decryptCode, "utf-8")
vm.runInContext(decryptCode, decryptFuncCtx);
// ! finally we can decrypt/deobf our strings
traverse(AST, deobfStrings)
I like to be able to see the code I'm using being output to a file, in-case something is going wrong, it makes it easier to fix it.
From here the script is still looking really rough, not even readable. That's fine though, we're very close! The next thing we need to do is deobfuscate those objects, aka objobf.
Before we can start on objobf, we will need to do "string concatenation". This is where you turn "x" + "y" + "z" into "xyz". We need to do this because there's a possibility that the string deobf caused an output like this object["k" + "e" + "y"]. Thankfully, this visitor is super easy. I found this visitor on github.com/SteakEnthusiast/Supplementary-AST-Based-Deobfuscation-Materials/blob/master/String%20Concealing a long time ago, it's never failed me. Huge shoutout to pianoman!
Now that we got that out of the way, let's do the main part. My approach to objobf this time was something I hadn't tried before, it ended up being way easier than my typical solution though. First I create a global variable let obfioObjMap = {}, this will store all of our objects by name with all of their properties. Next we need a visitor that populates that map:
const getObfioObjs = {
VariableDeclarator(path) {
const {node} = path;
if(!node.id || node.id.type != "Identifier" || !node.init || node.init.type != "ObjectExpression" || !node.init.properties || node.init.properties.length < 1) {
return
}
// ! further validation, just incase
let map = {}
let valid = true
for (var i = 0; i < node.init.properties.length; i++) {
var prop = node.init.properties[i]
if (!prop.key || !prop.value || prop.key.type != "Identifier") {
valid = false
break;
}
if (prop.value.type != "FunctionExpression" && prop.value.type != "StringLiteral" && prop.value.type != "MemberExpression") {
valid = false
break;
}
if (prop.key.name.length != 5) {
valid = false
break;
}
if (prop.value.type == "FunctionExpression" && prop.value.body.body[0].type != "ReturnStatement") {
valid = false
break;
}
map[prop.key.name] = prop.value
}
if (!valid) {
return
}
path.scope.crawl()
let binding = path.scope.getBinding(node.id.name)
if(!binding) {
return
}
var ID = t.identifier(makeid(20))
for(var i = 0; i < binding.referencePaths.length; i++) {
binding.referencePaths[i].replaceWith(ID)
}
obfioObjMap[ID.name] = map
path.remove()
}
}
You may notice that I've changed the name of the object's references before adding it to the map and deleting it. This is because, every so often, sometimes there can be duplicate names.
Now that the map is populated, we can go on to deobfuscate the objobf:
function getArgs(arguments, cutFirst) {
var out = []
for (var i = cutFirst ? 1 : 0; i < arguments.length; i++) {
out.push(arguments[i])
}
return out
}
const objDeobfMemberExpr = {
MemberExpression(path) {
const {
node
} = path;
if (!node.object || !node.property || node.object.type != "Identifier" || !obfioObjMap[node.object.name]) {
return
}
let map = obfioObjMap[node.object.name]
let key;
if (node.property.type == "Identifier") {
key = node.property.name
} else {
key = node.property.value
}
let value = map[key]
if (value.type == "StringLiteral") {
path.replaceWith(value)
return
}
if (value.type == "MemberExpression") {
map = obfioObjMap[value.object.name]
if (value.property.type == "Identifier") {
key = value.property.name
} else {
key = value.property.value
}
value = map[key]
path.replaceWith(value)
return
}
output += `FAILED (1): ${generate(node).code}\n\n`
},
CallExpression(path) {
const {
node
} = path;
if (!node.callee || node.callee.type != "MemberExpression" || !node.callee.object || !node.callee.property || node.callee.object.type != "Identifier" || !obfioObjMap[node.callee.object.name]) {
return
}
let map = obfioObjMap[node.callee.object.name]
let key;
if (node.callee.property.type == "Identifier") {
key = node.callee.property.name
} else {
key = node.callee.property.value
}
let value = map[key]
// ! replace functions
let retNode = value.body.body[0].argument
// ! call expression
if (retNode.type == "CallExpression") {
var callExprID;
// ! check if it's a reference to another object
if (retNode.callee.type == "MemberExpression") {
callExprID = retNode.callee
} else {
callExprID = node.arguments[0]
}
var args = []
if (node.arguments.length > 1 || retNode.callee.type == "MemberExpression") {
args = getArgs(node.arguments, retNode.callee.type != "MemberExpression")
}
path.replaceWith(t.callExpression(callExprID, args))
return
}
// ! BinaryExpression
if (retNode.type == "BinaryExpression") {
path.replaceWith(t.binaryExpression(retNode.operator, node.arguments[0], node.arguments[1]))
return
}
output += `FAILED (2): ${generate(node).code}\n\n`
}
}
You'll notice there's 2 parts here, one is for StringLiterals properties and the other is for FunctionExpressions properties. The MemberExpression code is just doing the StringLiteral, it's practically the same thing as replaceObjSimple. The difficult part comes with CallExpression, this is because we need to both figure out what the final output is but also persist the inputs to the function. This could be made harder but I won't give Twitter any funny ideas.
The way I go about doing the CallExpressions is by firstly identifying what exactly the FunctionDeclaration is doing. If it's a CallExpression on the return argument, we then know it's not doing math, we still need to check if it's a CallExpression to a MemberExpression though, since that would make the callee a different selector. Persisting the arguments is super easy once you recognize the pattern, if the callee type isn't a MemberExpression, then the callee is the first argument and the params are all the arguments except the first one. Otherwise, the arguments are just all the arguments. I wrote a nice helper function to do this. The only other thing to check is if the function is doing math, aka a BinaryExpression, that's pretty simple though, I won't explain that.
Now there's only one more thing left to do, at least in our deobfuscation script. We need to do "clean up". This means removing "dead code", aka code that can't be reached. This means those proxy functions from earlier that we never removed and these weird if statements:
if (!("rABTX" === "KEzBJ")) try {
const t = vr["sdp"] || o;
Or = lr(L([t[n[5] % 8] || "4", t[Ur[8] % 8]])), W["close"]();
} catch {} else try {
if ("udSfk" !== "NiOQr") {
const W = u["sdp"] || o;
ro = Gr(wr([W[n[5] % 8] || "4", W[n[8] % 8]])), t["close"]();
} else {
if (!xr["animate"]) return;
const n = hr["animate"](yr(Gr), u);
n["pause"](), n["currentTime"] = w(Sr / 10) * 10;
}
} catch {}
Doing the proxy functions is easy, I'll only be explaining the if statements. First I need to explain what we're looking at. We have two different if conditions here, !("thing" === "thing1") and "thing" === "thing1". This is important because it changes how the node.test.type returns and just generally how we interact with node.test and figure out which path to choose.
So when looking at an if stmt in ASTExplorer, you'll notice you have a test, consequent, alternate, etc. So if the test evaluates to true, aka 1 === 1, then the correct node to choose would be node.consequent. This obfuscation has a lot of annoying stuff in it though, you'll notice that the more you look into the different dead code's. Sometimes you won't have an else, instead the block that would execute will end with a return which would force the "dead code" to not run. This makes our job really annoying, we could deal with that, however, since the script is so small, I'd rather just do it manually instead of putting in the effort.
Here's what I have for the dead code cleanup:
function evalValue(left, right, op) {
switch (op) {
case "===":
return left == right
case "!==":
return left != right
}
}
const cleanupDeadCode = {
FunctionDeclaration(path) {
const {node} = path;
if(!node.id || node.id.type != "Identifier" || !node.body || !node.body.body || !node.params || node.params.length < 2 || node.body.body.length != 1 || node.body.body[0].type != "ReturnStatement") {
return
}
path.remove()
},
"IfStatement|ConditionalExpression"(path) {
const {
node
} = path;
if (!node.test || !node.consequent || node.test.type != "BinaryExpression" || !node.test.left || !node.test.right || node.test.left.type != "StringLiteral" || node.test.right.type != "StringLiteral") {
// ! handle if(!("x" !== "x")) { } else { } here
if (!node.test || !node.consequent || node.test.type != "UnaryExpression" || !node.test.argument || node.test.argument.type != "BinaryExpression" || !node.test.argument.left || !node.test.argument.right || node.test.argument.left.type != "StringLiteral" || node.test.argument.right.type != "StringLiteral") {
return
}
if (!evalValue(node.test.argument.left.value, node.test.argument.right.value, node.test.argument.operator)) {
path.replaceWithMultiple(node.consequent)
return
}
if(!node.alternate){
path.remove()
return
}
path.replaceWithMultiple(node.alternate)
return
}
if (evalValue(node.test.left.vaTypically, when this is presentlue, node.test.right.value, node.test.operator)) {
path.replaceWithMultiple(node.consequent)
return
}
path.replaceWithMultiple(node.alternate)
}
}
At this point, we look to be done!
Conclusion
The script is still sort-of hard to read still. In the next part, I'll be going over how I went in and reverse engineered it by hand to see how it worked. There I'll be making it extremely readable!
This code will be published on my GitHub at github.com/obfio/twitter-tid-deobf. If you enjoyed this article, feel free to star the repository!
References
GitHub for this code: github.com/obfio/twitter-tid-deobf
PianoMan GitHub (deobfuscation tutorials): github.com/SteakEnthusiast